
Introduction
Retrieval-augmented generation (RAG) models are transforming natural language processing by combining the strengths of large language models with efficient information retrieval. At a high level, RAG systems retrieve relevant context passages from a database in response to a query and integrate these with an LLM to generate a final output.
This leverages the reasoning capacity of LLMs while grounding them in external knowledge. Initially, RAG took the form of simple pipeline systems that fed retrieved passages to LLMs as context for response generation. But rapid innovation soon followed. Models are advancing with sophistications like learned retrievers that transform queries, selective mechanisms over retrieved knowledge, and multi-step reasoning chains. Learn more about RAG in this blog post
While basic Retrieval-augmented generation pipelines retrieve context via simple similarity searches, advanced techniques can significantly enhance performance. Methods like fusion retrieval and query transformation produce more nuanced, contextually relevant results by reformulating queries and combining multiple retrieval strategies. As RAG advances, it is enabling intelligent applications across domains like finance, healthcare, and customer service.
Fusion Retrieval for Advanced RAG
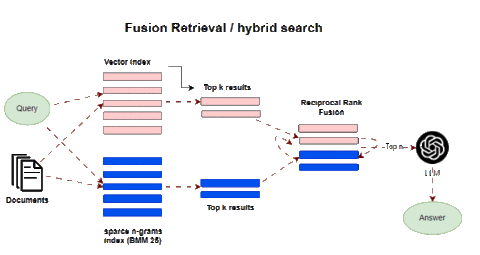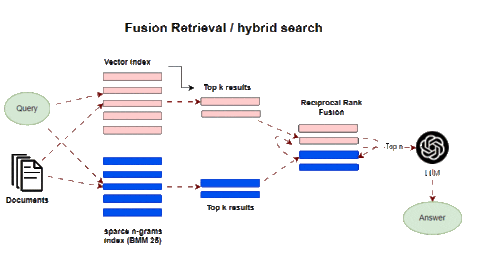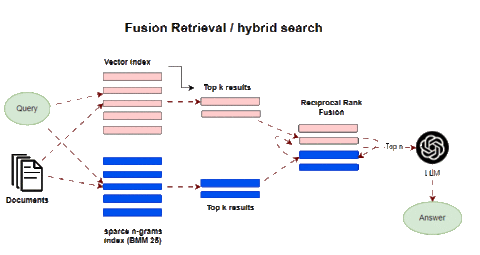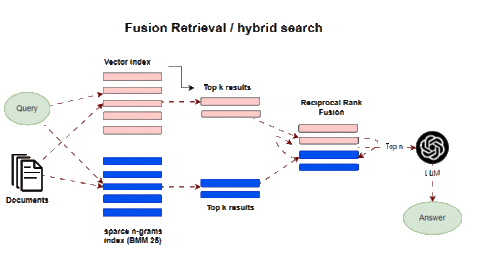
Image by Author
Fusion retrieval, also known as hybrid search, combines multiple complementary retrieval methods to enhance results. A classic approach is integrating keyword-based sparse matching with semantic dense retrievers. Sparse methods like BM25 and TF-IDF are industry-standard for search relevancy. They match keywords and terms between queries and documents. This excels at precision for literal query matches.
Dense retrieval based on embeddings derives semantic similarity between query and context vectors. This identifies relevant passages from a latent meaning perspective. Individually, each method has limitations. Keyword matching lacks semantic understanding. Dense matching can retrieve tangentially related passages. Fusion integrates the two to achieve improved recall and relevance. Sparse retrievers pinpoint specific keyword matches, while dense retrievers add relevant passages that may lack exact query terms but enrich topical context. After concatenating results from both retrievers, algorithms like reciprocal rank fusion (RRF) re-rank passages by weighting and blending both result sets. This produces a fused list superior to either alone.
For example, a query on “ML acceleration hardware” would retrieve passages mentioning those keywords via a sparse search. Dense retrieval would add related sections on GPUs, FPGAs, and specialized AI chips. Fusion ranking blends these optimally.
In LangChain this is implemented in the Ensemble Retriever class, combining a list of retrievers you define, for example, a faiss vector index and a BM25-based retriever, and using RRF for reranking.
Optimizing Retrieval through Query Transformations
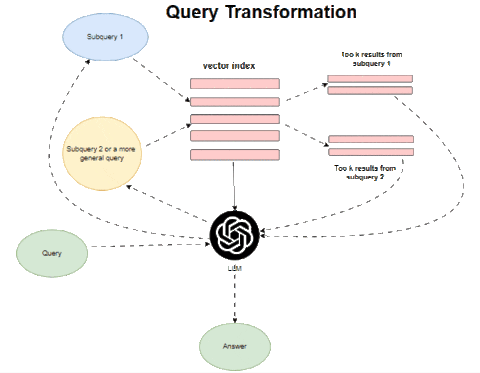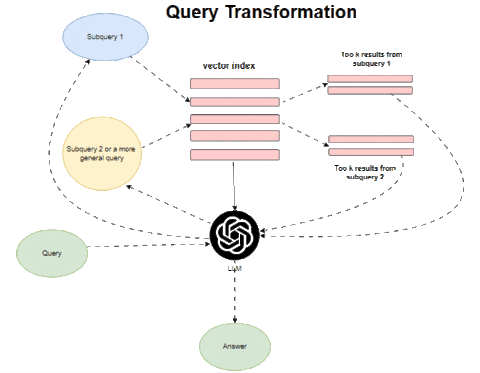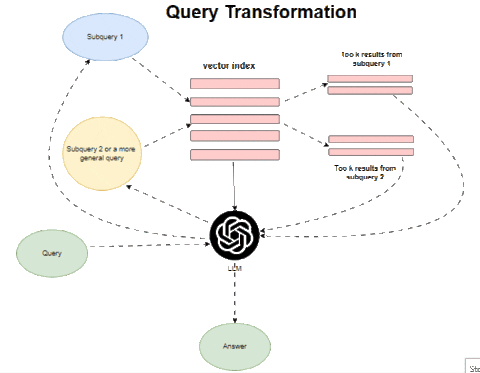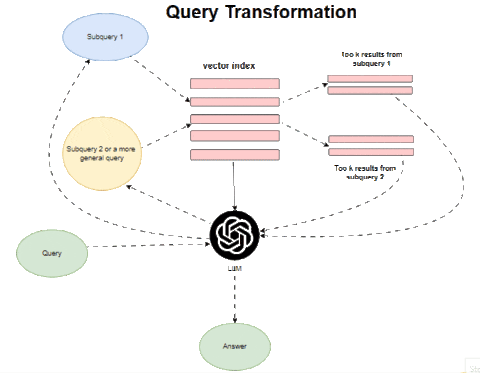
Image by Author
Query transformations leverage the reasoning capacity of large language models to rewrite or expand queries before retrieval. This better aligns retrieved results with the user’s underlying informational need. Two key techniques are stepback prompting and query paraphrasing or re-writing. Stepback prompting uses the LLM to generate a more general query which provides useful topical context when retrieved. The LLM then specializes this general query back to the original to maintain specificity.
For example, a query about “RAG techniques” could retrieve passages on natural language processing first, before retrieving on the narrower Retrieval-augmented generation topic. This provides background knowledge to aid the LLM’s comprehension.
Query paraphrasing reformulates the original query into multiple variations. For instance, a question on comparing two frameworks’ GitHub stars could expand into parallel queries asking for each framework’s stars independently. The multiple result sets provide diverse perspectives.
Existing Limitations and Potential Solutions
- Query Depth and Over Explanation: RAG Fusion attempts to deeply understand queries by generating multiple sub-queries, which can sometimes result in overly detailed or lengthy responses.
Potential Solutions:- Use summarization techniques to distill key points from retrieved documents, providing users with concise and relevant information.
- Implement ranking and filtering mechanisms for sub-queries to prevent overexpansion, ensuring that only the most relevant and informative passages are included in the final response.
- Context Limitations: Managing multiple queries and diverse documents within the context window of the language model can strain its capacity, potentially leading to less coherent outputs as context is lost.
Potential Solutions:- Experiment with adjusting the context window size to find the optimal balance between capturing relevant context and maintaining coherence in responses.
- Iteratively refine prompting strategies to focus the language model on key contextual elements.
Applications of Advanced RAG
RAG is enabling transformative AI applications across sectors by grounding language models in specialized knowledge.
- In finance, RAG is powering conversational systems that leverage financial data to answer investor queries. They can interpret market trends, analyze securities, and offer personalized investment insights – capabilities far exceeding unaugmented models. Auquan is a SaaS-based Intelligence Engine that leverages RAG to help financial professionals discover hidden value in seemingly worthless data and identify financially material ESG, reputational, and regulatory risks on more than 500 private companies, equities, infrastructure projects, and other entities. Avkalan is also in the race to develop
- Healthcare is utilizing RAG for improved diagnostic and triage support. By referencing patient histories, medical ontologies, and expert knowledge bases, these systems can provide detailed assistance to doctors and nurses. RAG also shows promise for public health applications like accelerating research review.
- Customer service and e-commerce are deploying RAG chatbots that incorporate product specs, user manuals, transaction records, and enterprise data. This allows smooth conversational experiences that resolve customer needs based on business contexts.
- Government and legal applications are also emerging, with RAG applied to areas like streamlining public services and assisting in legal research. Models augmented with statutes, regulations, and case law can reason about compliance and precedence.
Avkalan.ai used its expertise in advanced retrieval augmented generation and artificial intelligence to make a custom Legal AI for a client. By using leading-edge RAG techniques on a large scale, Avkalan.ai built an innovative legal help system fueled by a huge knowledge base.
Case Study: Massive Scaling of RAG
Recent research from Cohere and Pinecone provides an impressive case study on the scalability of advanced RAG systems. Their experiments indexed up to 1 billion web pages, allowing evaluation of its performance at an unprecedented scale across models like GPT-3, GPT-4, and smaller open-source LLMs.
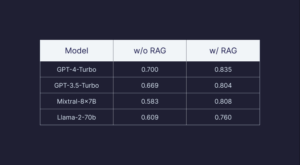
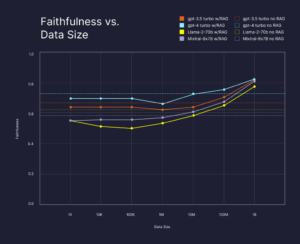
Analysis showed massive data consistently improved answer faithfulness – for GPT-4, RAG boosted faithfulness by 13% over no retrieval, even on data the LLM was trained on. Smaller LLMs also reached a high faithfulness of 80% given sufficient retrievable data, competitive with GPT-4 without RAG.
This demonstrates advanced techniques like fusion retrieval and optimizations like Pinecone’s indexing help RAG scale remarkably well. The massive external data provided a nuanced context for the LLMs to generate reliable, grounded responses. As this research shows, advanced pipelines unlock performant question answering, even from smaller or private LLMs, when provided with expansive domain-specific corpora.
Conclusion
Advanced techniques are rapidly progressing RAG capabilities, enabling context-aware language models that integrate external knowledge. As methods like fusion retrieval and query transformation enhance results, powering more intelligent applications across domains. Though RAG is still evolving, its transformative impact is already evident. With continued research, these models may soon simulate even greater levels of reasoning, comprehension, and creativity.