
In the realm of artificial intelligence and machine learning, the advent of Retrieval Augmented Generation (RAG) marks a pivotal shift. Gone are the days of constantly fine-tuning models each time new data emerges. RAG elegantly resolves this by seamlessly integrating the latest information, offering a robust solution to the limitations of traditional generative models.
Introduction
This article serves as a definitive guide to Retrieval Augmented Generation. It delves deep into the mechanics of RAG, illuminating its essential components, the technology that powers it, and its practical applications. Additionally, we will navigate through the challenges and the promising future that RAG holds, offering a lucid and comprehensive understanding of its transformative impact on AI and machine learning.
Background and Evolution of RAG
The evolution of language models in artificial intelligence has been a journey towards increasingly sophisticated and versatile systems, a path marked by significant milestones in the development of natural language processing (NLP) and machine learning.

Image by Author
Early Stages of Language Models
- Rule-Based Systems: Early AI systems relied on manually coded rules and logic to process and generate language. These systems were limited by their inability to learn or adapt beyond their predefined rules.
- Statistical Models: With the advent of statistical methods, language models began to use probabilities and patterns derived from large text datasets. This shift marked a significant improvement in the ability of models to predict and generate text.
Rise of Neural Networks and Deep Learning
- Neural Networks: The introduction of neural networks, particularly recurrent neural networks (RNNs) and later, Long Short-Term Memory (LSTM) networks, allowed for more sophisticated handling of sequential data like text.
- Transformers and Pre-trained Models: The development of the transformer architecture, exemplified by models like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pretrained Transformer), revolutionized NLP. These models could process text in a non-sequential manner, capturing complex language patterns more effectively.
Retrieval-Augmented Methods
- Combining Retrieval with Generative Models: RAG represents an evolutionary leap by integrating retrieval-based methods with advanced generative models. Instead of relying solely on pre-trained data, RAG systems actively retrieve information from external databases or documents in real-time to inform their responses.
Core Concepts and Technologies in Retrieval Augmented Generation

Image by Author
Retrieval Augmented Generation (RAG) is an advanced technique in the field of artificial intelligence and natural language processing. It’s a hybrid approach that combines the strengths of two key methodologies: retrieval-based methods and generative models. Let’s break down these components to understand RAG better:
Retrieval-based Methods
Starting with the retrieval-based methods, these are approaches in AI that involve searching through a database or a collection of documents to find relevant information. The retrieval process typically involves querying a large dataset and extracting pieces of information that are relevant to the query. This method is common in search engines and question-answering systems.
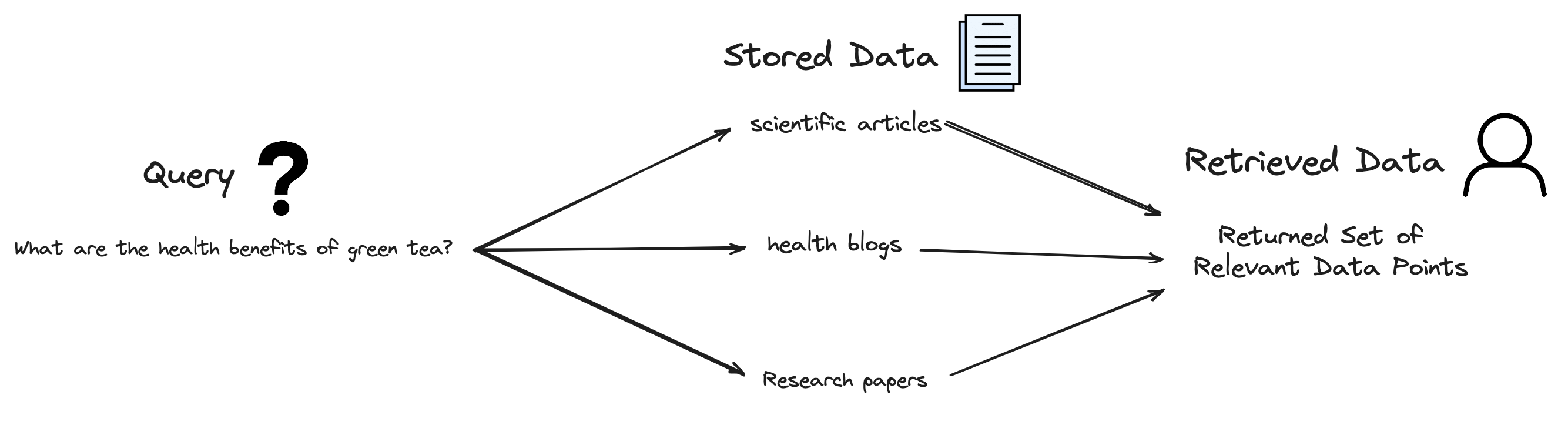
Image by Author
To better understand such an approach let’s give a brief example. Suppose we have a given query that is, “What are the health benefits of green tea?” The RAG system will search through its database (like scientific articles, health blogs, etc.) to find relevant information about green tea’s health benefits.
This is the main idea behind retrieval-based generation, in which for the model to generate the given output, it first must find the given piece of text/info for it to generate such an answer.
Generative Models
These are algorithms that can generate new content. In the context of language processing, generative models are trained on large datasets of text and can produce human-like text based on the input they receive. These models learn patterns and structures of language, enabling them to create coherent and contextually relevant text.
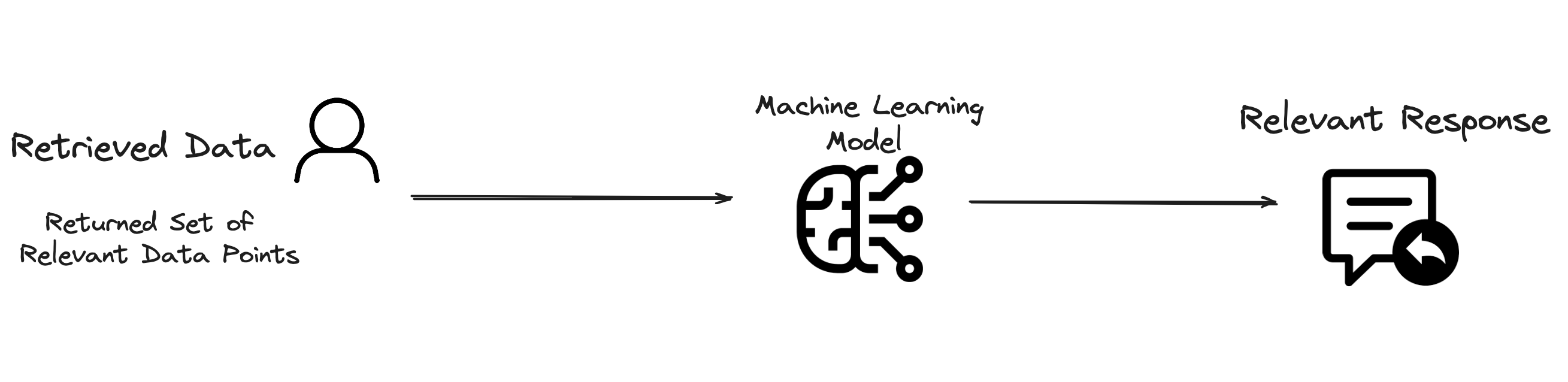
Image by Author
Continuing on with the previous example: Using the retrieved data on green tea, the generative model now crafts a comprehensive answer, which could include points like “Green tea is rich in antioxidants, which can reduce the risk of certain diseases.”
Retrieval Augmented Generation
In RAG, the retrieval process is used to gather relevant information from a vast dataset, which is then fed into a generative model. The generative model uses this retrieved information to create more accurate, informative, and contextually relevant responses. This combination allows the system to leverage both the extensive knowledge available in existing databases and the creative, nuanced language generation capabilities of modern AI models.
Practical Retrieval Augmented Generation Python Example
The objective of the following implementation is to streamline the Retrieval Augmented Generation (RAG) process by introducing a simplified yet effective approach.
This method involves emulating key aspects of RAG through a custom-designed data retrieval function. This function is tailored to intelligently extract relevant information from a provided context. Once it is complete, the targeted question and the contextually relevant information is subsequently fed into a ChatGPT model. The ChatGPT model, renowned for its generative prowess, processes this combined input to generate a comprehensive and context-aware response.
This approach not only simplifies the RAG process but also maintains the essence of its functionality, delivering accurate and contextually enriched answers.
Step 1: Installing and Importing the Necessary Libraries
| !pip install openai
import openai import os from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.metrics.pairwise import cosine_similarity import numpy as np from openai import OpenAI |
Step 2: Setting up your OpenAI API key
os.environ[“OPENAI_API_KEY”] = “Insert your OpenAI key here”
client = openai.Client() |
Step 3: Defining a Data Retrieval Function
| def retrieve_relevant_context(question, context, num_sentences=1):
sentences = context.split(‘.’) vectorizer = TfidfVectorizer().fit([question] + sentences) question_vec = vectorizer.transform([question]) sentences_vec = vectorizer.transform(sentences) similarities = cosine_similarity(question_vec, sentences_vec).flatten() relevant_indices = np.argsort(similarities, axis=0)[-num_sentences:] relevant_context = ‘. ‘.join([sentences[i] for i in relevant_indices]) return relevant_context |
Step 4: Defining a Data Generation Function
| def generate_response(question, context):
prompt = f”Question: {question}\nContext: {context}\nAnswer:” response = client.chat.completions.create( model=”gpt-3.5-turbo”, messages=[ {“role”: “system”, “content”: “You are a helpful assistant.”}, {“role”: “user”, “content”: question}, {“role”: “user”, “content”: context} ] ) return response.choices[0].message.content |
Step 5: Testing our model with an example
| context = “Marcus Marilo is 29 years old.”
question = “How old is Marcus Marilo?” relevant_context = retrieve_relevant_context(question, context) response = generate_response(question, relevant_context) print(“Response:”, response) |
Response: According to the information provided, Marcus Marilo is 29 years old.
Benefits of Retrieval Augmented Generation Models
Applications of RAG are particularly significant in areas where the accuracy of information and the ability to answer complex queries are paramount.
Enhanced Knowledge
RAG systems extend their reach to external databases, allowing them to provide information that goes beyond their initial training. This feature ensures that the responses are not only accurate but also reflect the most current information available.
Example: In an academic research context, a RAG-powered tool is asked about the latest developments in quantum computing. It retrieves and synthesizes information from recent scientific publications, providing an up-to-date and comprehensive overview.
Contextual Relevance
RAG prioritizes the context of each query, ensuring that the information used for generating responses is highly relevant. This leads to outputs that are more precisely aligned with the user’s needs and questions.
Example: In a travel planning chatbot, when a user inquires about the best vegan restaurants in Paris, RAG retrieves and presents a list of top-rated vegan eateries in Paris, tailored to the user’s dietary preferences and location.
Highly Flexible
RAG’s adaptable nature allows it to be effectively implemented in various applications like chatbots, content creation, and advanced search and question-answering systems.
Example: For a financial analyst, a RAG system could analyze and summarize trends in stock market data when asked about the performance of specific industry sectors, offering insights drawn from a wide range of financial databases and reports.
No Need for Extensive Fine-Tuning to Incorporate New Data
Lastly and most importantly, as RAG models are designed to dynamically retrieve information from external sources, this allows them to access and utilize the latest data without the need to be retrained or fine-tuned extensively.
This attribute makes RAG systems both time-efficient and adaptable, as they can stay current with the latest information or trends without undergoing a lengthy update process.
Example: A RAG model can automatically pull in the latest news articles and reports from its connected databases, instantly providing users with up-to-date information. This capability is especially crucial in fast-changing domains like news, finance, or scientific research, where staying current with the latest information is essential.
Applications of RAG
Retrieval Augmented Generation (RAG) has introduced a transformative approach in various fields, significantly enhancing the capabilities of AI-driven applications. The idea behind all aforementioned RAG applications is the retrieval of the necessary data before performing the intended tasks.
- Chatbots and Customer Service: In customer service, RAG-equipped chatbots can access up-to-date information from external databases, providing accurate and relevant responses to customer inquiries. This capability dramatically improves the quality of customer interactions, fostering more effective and satisfying customer service experiences.
- Search Engines: RAG can revolutionize search engines by combining the comprehensive knowledge retrieval of traditional search with the nuanced understanding and response generation of AI. This integration allows for more precise and contextually relevant search results, moving beyond keyword matching to understanding the intent and context of queries.
- Content Creation: In the realm of content creation, RAG can assist in generating informative and contextually rich content. Whether it’s news articles, reports, or creative writing, RAG can pull in relevant facts and data, ensuring that the content is both engaging and substantiated by accurate information.
- Medical Diagnosis and Research: In the medical field, RAG can aid in diagnostics by retrieving and synthesizing relevant medical literature and case studies, assisting healthcare professionals in making informed decisions.
Challenges in Retrieval Augmented Generation Systems
Implementing Retrieval Augmented Generation (RAG) systems presents several challenges and limitations that are critical to address for their effective and ethical application. Some of those challenges include:
Ensuring High Data Quality
One primary challenge is ensuring the quality of data used in RAG systems. Since these models rely heavily on external data sources for information retrieval, the accuracy and relevance of the retrieved data are paramount. Poor data quality can lead to misinformation, inaccuracies, and contextually irrelevant outputs, undermining the system’s effectiveness.
High Computational Resources
Another significant hurdle is the computational resources required for RAG systems. The process of retrieving information from large datasets and integrating it with generative models demands substantial computational power. This can make RAG systems resource-intensive, potentially limiting their accessibility and scalability, especially for smaller organizations or in resource-constrained environments.
Susceptibility to Biases
Additionally, RAG models, like all AI systems, are susceptible to biases. These biases can stem from the training data or the external data sources used for retrieval. If unchecked, these biases can propagate through the system’s outputs, leading to biased or unfair results. Ensuring that RAG models are trained on diverse, unbiased datasets and incorporating checks for bias in retrieved data are crucial steps in mitigating this issue.
Conclusion
In summarizing the expansive realm of Retrieval Augmented Generation (RAG), we glimpse the future of artificial intelligence — a future where the boundaries of machine understanding and human-like contextualization are continually being redefined. RAG is not just a technological advancement; it is a paradigm shift, ushering in an era where AI systems interact with and comprehend the world with unprecedented depth and nuance.
As we stand at this juncture, witnessing the ongoing evolution of RAG, it’s clear that we are partaking in a significant chapter in the story of AI. This guide aims not just to inform but to inspire — to kindle a sense of curiosity and anticipation for what the future holds. RAG is more than a technological tool; it’s a beacon leading us towards a more intelligent, informed, and interconnected world.