
Exploring the Intricacies of the Top 3 Vector Database: Uncovering Their Remarkable Contributions to Advancements in Technology.
How Does a Vector Database Work
Traditional databases store basic information like words and numbers in a tabular format. In contrast, vector databases handle intricate data known as vectors and employ distinct methods for searching. While conventional databases seek precise data matches, vector databases search for the closest match using specific measures of similarity.
Vector databases employ specialized search techniques, such as approximate nearest neighbour (ANN) search, incorporating methods like hashing and graph-based searches. Understanding how vector databases function and their distinctions from traditional relational databases like SQL, it is essential to grasp the concept of embeddings.
Unstructured data, such as text, images, and audio, lacks a predetermined format, creating challenges for traditional databases. Transforming this data into numerical representations through embeddings enables its utilization in artificial intelligence and machine learning applications.
Embedding is akin to assigning a unique code to each item, be it a word, image, or another entity, and capturing its meaning or essence. This code helps computers understand and compare these items in a more efficient and meaningful way. Think of it as condensing a complex book into a concise summary that retains the key points.
Specialised neural networks designed for the task typically accomplish this embedding process. For instance, word embeddings convert words into vectors, bringing words with similar meanings closer together in the vector space. This transformation enables algorithms to grasp relationships and similarities between items.
In essence, embeddings function as a conduit, transforming non-numeric data into a format that machine learning models can handle, enabling them to identify patterns and relationships in the data more effectively.
Characteristics of an Effective Vector Database
Vector databases are effective tools for exploring unstructured data such as photos, movies, and texts without depending on human-generated labels or tags. When combined with modern machine learning models, these talents have the potential to transform several industries, ranging from e-commerce to healthcare. Here are some prominent qualities that make vector databases revolutionary:
1. Scalability and Adaptability
An efficient vector database may easily expand over numerous nodes as the amount of data increases to millions or billions of items. Top vector databases provide flexibility by allowing users to adjust the system in response to changes in insertion rate, query rate, and underlying technology.
2. Multi-user functionality and Data Confidentiality
It is typical for databases to be able to accommodate numerous users. Simply generating a fresh vector database for every user is not efficient. Vector databases prioritize data isolation to ensure that changes made to one data collection are not visible to others unless expressly shared by the owner. This feature not only enables multi-tenancy but also guarantees the confidentiality and protection of data.
3. Extensive API Suite
An authentic and efficient database provides a comprehensive range of APIs and SDKs. This feature ensures that the system can effectively communicate with a variety of applications and be efficiently controlled. Pinecone and other top vector databases offer Software Development Kits (SDKs) in many programming languages, including Python, Node, Go, and Java, allowing for versatile development and administration.
4. Intuitive interfaces
Intuitive interfaces are vital for enhancing the usability of vector databases, offering benefits such as reduced learning curves, lower training costs, increased productivity, and faster insights. They streamline navigation, provide visual aids, and simplify workflows, leading to improved user experiences and quicker adoption. These interfaces empower users to explore features independently, speeding up onboarding and minimizing errors. With intuitive visualizations and search tools, users can uncover patterns in data swiftly, facilitating collaboration and informed decision-making. Examples include interactive dashboards, drag-and-drop functionality, contextual help, and search/filter tools. Overall, investing in intuitive interfaces unlocks the full potential of vector databases, driving efficiency and effectiveness in data analysis and decision-making processes.
More Characteristics of Vector Databases
- Security Features:
- Confidentiality: Using encryption and access control to protect data from unauthorized access.
- Integrity: ensures that data remains unaltered and tamper-proof.
- Authentication and Authorization: Verifies user identities and restricts access based on assigned permissions.
- Reliability:
- High Availability: Guarantees the database’s consistent uptime and accessibility, minimizing downtime and ensuring data availability.
- Disaster Recovery: robust mechanisms to recover from hardware failures or software issues with minimal data loss.
- Monitoring and Alerting: Proactive monitoring of system health and performance, as well as timely alerts for potential issues.
- Ease of Use:
- Intuitive Interface: A user-friendly interface with clear navigation, visual aids, and self-service capabilities for efficient data management.
- Simple Data Management: Straightforward procedures for data ingestion, indexing, querying, and visualization.
- Documentation and Tutorials: To facilitate learning and troubleshooting, comprehensive documentation and tutorials are provided.
- Community Support:
- Active Community: A large and engaged user community provides resources, forums, and support channels.
- Knowledge Base and Tutorials: Extensive documentation, tutorials, and FAQs to address commonly encountered issues.
- Responsive Support: In case of technical difficulties, the community or vendor will provide efficient and timely assistance.
- Integration Capabilities:
- Seamless Integration: The ability to integrate with existing data pipelines, frameworks, and applications to ensure efficient data flow and utilization.
- Supported Programming Languages: To enable developers to work with the database using familiar tools.
- Open APIs: well-documented APIs that allow developers to build custom applications and functionalities.
Exploring Three of the Best Vector Databases in 2024
1. Chroma
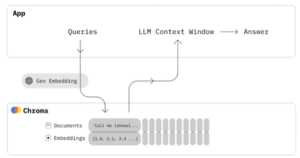
Chroma is an open-source embedding database that facilitates the building of Large Language Model (LLM) applications by offering a plug-and-play method for integrating knowledge, facts, and abilities. The Chroma DB lesson emphasizes its user-friendly features, enabling easy administration of text documents, conversion of text to embeddings, and conducting similarity searches.
Salient Features:
- The extensive functionality includes complex features including searches, filtering, density estimations, and more capabilities.
- It is compatible with both LangChain (Python and JavaScript) and LlamaIndex.
- The API utilized in Python notebooks smoothly expands to production clusters, guaranteeing a seamless shift from development to deployment.
Pros:
- Open-source and free to use: ideal for cost-conscious individuals and organizations.
- Flexible querying capabilities: supports diverse querying options for various use cases.
- Strong focus on NLP research and development: an excellent choice for building large language model applications.
- Easy to set up and use: The user-friendly interface and Python/Go SDKs simplify development.
Cons:
- Emerging community and ecosystem: less support compared to established platforms.
- May not be ideal for large-scale deployments: Scalability limitations compared to other options.
- Managed service costs: While a free tier exists, large deployments might encounter higher costs with the pay-as-you-go managed service.
2. Milvus
What problem does it solve
Milvus is a vector database that is open-source and specifically created to support vector embedding, effective similarity search, and applications in artificial intelligence. The project obtained its release in October 2019 under the open-source Apache License 2.0 and is now a graduate project supported by the LF AI & Data Foundation.
The tool streamlines the search for unstructured data and provides a consistent user experience regardless of the deployment setting. All components in the refactored version of Milvus 2.0 are stateless to enhance flexibility and adaptability.
Milvus can be used for image search, chatbots, and chemical structure search.
Primary characteristics
- Searching through vast amounts of vector datasets in milliseconds.
- Managing unstructured data is straightforward.
- A dependable vector database with constant availability.
- Extremely scalable and versatile.
- Explore hybrid.
- A unified Lambda framework.
- Endorsed by the community and recognized by the industry.
Pros:
- Highly scalable and performant: handles diverse workloads and scales effectively for large datasets.
- Large and active community: extensive resources, tutorials, and support are available.
- Supports diverse data types: Handles more data types compared to Chroma DB.
- Open-source with commercial licenses: Free versions have limitations; paid licenses offer additional features and enterprise support.
Cons:
- More complex setup: Requires containerization expertise and DevOps knowledge.
- Lacks certain advanced features: Doesn’t natively support geospatial or date-time data types.
- Inconsistent security features: OAuth and LDAP implementation might require attention.
3. Pinecone
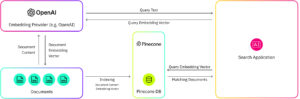
Pinecone addresses the difficulties related to high-dimensional data with its specialized vector database platform. Pinecone provides advanced indexing and search features that enable data engineers and data scientists to create and deploy large-scale machine learning systems for processing and analyzing high-dimensional data efficiently.
Pinecone’s key attributes are:
- Completely supervised service
- Extremely scalable
- Live data ingestion refers to the process of continuously collecting and importing
- real-time data into a system or database.
- Fast search
- Integration with LangChain
For additional information on Pinecone, refer to Moez Ali’s Mastering Vector Databases with Pinecone Tutorial by Moez Ali on Data Camp.
Pros:
- Very easy to use and developer-friendly: great for developers new to vector databases.
- It focuses on real-time search and fast scalability. Ideal for applications requiring rapid responses.
- Free tier and pay-as-you-go pricing: A cost-effective solution for starting projects or dealing with fluctuating workloads.
- A large and active community offers various resources and support options.
Cons:
- Commercial platform: can be more expensive for large-scale deployments compared to open-source options.
- Limited querying capabilities: less flexible querying options compared to Chroma DB or Milvus.
- Sparse technical documentation: may require exploration through the community for specific answers.
Comparison Table of DB
| Feature | Chroma DB | Milvus | Pinecone |
| Performance & Scalability | Scales horizontally & vertically, good query performance | Scales horizontally, high performance for diverse workloads | Scales horizontally, focus on fast ingestion & retrieval |
| Ease of Use & Integration | Easy to set up and use Python and Go SDKs | More complex setup & requires containerization, diverse SDKs | Very easy & developer-friendly, Python & Javascript SDKs |
| Community Support & Ecosystem | Emerging community, smaller ecosystem | Large & active community with, a growing ecosystem | Large & active community, established ecosystem |
| Cost Efficiency | Open-source & free to use, managed service available (pay-as-you-go) | Open-source & free with limitations, commercial licenses available | Free tier, pay-as-you-go pricing based on usage |
How to Select the Appropriate Vector Database for your Project
When selecting a vector database for your project, take into account the following factors:
- Do you require a technical team to administer the database, or are you looking for a completely managed database service?
- Do you possess the vector embeddings, or do you require a vector database platform to help you in creating them?
- Latency requirements, whether batch or online,
- Inside the team, there is developer expertise.
- The tool’s learning curve.
- The solution’s reliability.
- Costs associated with implementing and maintaining a system.
- Security and adherence to regulations.
Conclusion
Vector databases are essential for storing and retrieving high-dimensional vectors quickly, especially in the field of artificial intelligence (AI), where models like GPT-3 create and handle these vectors. Large Language Models (LLMs) like GPT-3 depend significantly on vector databases to handle the vast and intricate vectorized data they generate. Vector databases play a crucial role in AI and machine learning by efficiently managing the multi-dimensional data vectors produced by these sophisticated models, offering tailored solutions for various applications like recommendation systems and genetic analysis. The rise of several vector databases such as Chroma, Pinecone, and Milvus demonstrates the increasing significance of these technologies in influencing the future of data processing and analysis in the AI-driven age.