

Few-Shot Named Entity Recognition: A Comprehensive Exploration
Named Entity Recognition (NER) stands as a cornerstone in Natural Language Processing (NLP), playing a pivotal role in deciphering and categorizing entities within textual data. These entities span various domains, including individuals, organizations, locations, and more. While state-of-the-art large language models (LLMs) have showcased remarkable performance in diverse NLP tasks, including few-shot NER, it’s essential to recognize the existence of simpler solutions that offer cost-effective alternatives. In this blog post, we delve into the intricacies of few-shot NER, examining its significance and exploring the current state-of-the-art methods.
The Significance of LLMs in NER
At its core, NER involves the identification and classification of named entities in text, assigning them to predefined categories such as people, organizations, locations, dates, and more. This task is widely adopted across various industries, serving as a foundational step in numerous NLP applications. For instance, in customer support, automated systems leverage NER to identify the intent of incoming requests, streamlining the process of routing them to the appropriate teams. In healthcare, professionals can quickly extract relevant information from reports using NER, enhancing efficiency.
Several approaches exist for NER, ranging from simple dictionary-based methods to more sophisticated machine learning and deep learning-based techniques. The dictionary-based approach involves matching vocabulary within the text, but its scalability is limited. Rule-based approaches leverage morphological or contextual rules, while machine learning-based methods learn feature-based representations from training data, overcoming the limitations of dictionary and rule-based approaches. Deep learning-based approaches excel at learning complex relationships and require less manual feature engineering.
Core Mechanisms of NER in LLMs
Named Entity Recognition (NER) in Large Language Models (LLMs) relies on various methods and techniques to effectively identify and categorize named entities within text. These core mechanisms encompass a range of approaches tailored to address the challenges of adapting pre-trained models to specific domains and extracting meaningful entities with high accuracy. Let’s explore these methods:
-
Prototypical Networks:
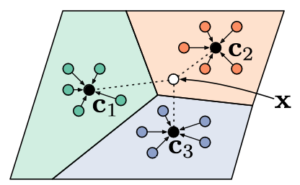
Prototypical networks represent a fundamental method in few-shot NER tasks, offering a structured approach to entity classification. Initially proposed by Jake Snell et al., prototypical networks have gained traction for their effectiveness in adapting pre-existing models to new domains with limited labeled data.
When presented with a support set containing a few in-domain examples, prototypical networks utilize the underlying representations of tokens within a deep-learning model to compute vector representations for each token. These representations are then grouped by entity type, such as Person or Organization, and averaged to generate prototype vectors representing each entity type. During inference, the model calculates token representations for new data and assigns them to the entity type with the closest prototype vector, facilitating accurate classification.
Variations of prototypical networks, such as instance-based metrics introduced by Yi Yang and Arzoo Katiyar, offer alternative approaches to entity classification by considering the distance between individual tokens in the support set. Additionally, methods proposed by Meihan Tong et al. explore the use of multiple prototypes for the O-class tokens, addressing challenges related to semantic representation.
-
Contrastive Learning:
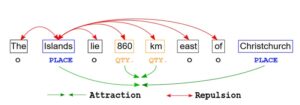
Contrastive learning provides another powerful technique for few-shot NER tasks, aiming to represent data points within a model in a manner that emphasizes similarities and differences. By adjusting token representations during model adaptation, contrastive learning promotes clustering of tokens belonging to the same entity type while pushing tokens of different types apart.
Illustrated by studies such as the work by Sarkar Snigdha Sarathi Das et al., contrastive learning dynamically adjusts token representations to minimize the distance between tokens of the same category while increasing the separation between tokens of different categories. This process enhances the model’s ability to discern subtle differences between entities and improves overall classification accuracy.
-
Meta-learning:
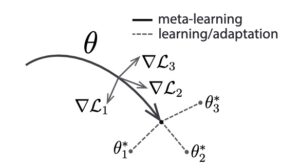
Meta-learning, also known as learning to learn, enables models to quickly adapt to new tasks or domains with minimal labeled data. Techniques like Model-Agnostic Meta-Learning (MAML), pioneered by Finn et al., train models to efficiently fine-tune their parameters based on a small number of examples.
Applied to few-shot NER by Ma et al., MAML combines with prototypical networks to identify initial model parameters conducive to rapid adaptation to new entity classes. By learning task-sensitive representations, meta-learning empowers models to generalize effectively and achieve state-of-the-art performance on datasets like Few-NERD.
-
Leveraging Large Language Models (LLMs):
Modern LLMs offer unparalleled capabilities in few-shot learning, making them indispensable for NER tasks with limited labeled data. Despite the token-level labeling nature of NER tasks conflicting with the generative nature of LLMs, recent research has explored innovative approaches to leverage their strengths effectively.
Studies like that of Ruotian Ma et al. explore prompting NER without templates, fine-tuning LLMs to predict representative label words for named entity classes. Meanwhile, GPT-NER proposed by Shuhe Wang et al. transforms NER sequence labeling into a text generation task, harnessing the natural language generation capabilities of LLMs for improved performance in few-shot scenarios.
-
Few-Shot NER Datasets:
Robust evaluation of few-shot NER models relies on high-quality datasets that accurately capture the challenges of real-world applications. The introduction of Few-NERD by Ding et al. represents a significant step forward, providing a standardized benchmark for assessing the generalization and knowledge transfer capabilities of models.
Few-NER features labeled entities categorized into coarse-grained and fine-grained types, facilitating comprehensive evaluation across different subsets. By ensuring the availability of publicly accessible test data, datasets like Few-NERD enable researchers to compare and evaluate various models systematically.
Application of NER using LLMs
Named Entity Recognition (NER) powered by Large Language Models (LLMs) finds diverse applications across various industries and domains, revolutionizing information extraction and enhancing decision-making processes. The versatility and adaptability of NER with LLMs enable organizations to streamline operations, improve user experiences, and unlock valuable insights from unstructured text data.
- Information Extraction: NER using LLMs facilitates precise extraction of specific entities, such as names of people, organizations, and locations, from unstructured text data. This capability is invaluable in applications like news analysis, content categorization, and data mining, where identifying key entities enables efficient retrieval and organization of information.
- Chatbots and Virtual Assistants: Integrating NER with LLMs enhances the capabilities of chatbots and virtual assistants, empowering them to understand and respond to user queries with relevant information. By identifying entities within the conversation, these systems deliver more accurate and context-aware responses, thereby enhancing user satisfaction and engagement.
- Biomedical and Clinical Text Analysis: In the healthcare domain, NER powered by LLMs plays a critical role in extracting important entities from biomedical and clinical texts. From medical entity recognition to disease identification and pharmacological entity extraction, NER with LLMs facilitates advanced text analysis, contributing to medical research and improving healthcare applications.
Challenges in Named Entity Recognition with Large Language Models
While LLMs offer exciting possibilities for NER, it’s crucial to acknowledge the challenges and limitations associated with their application. Here, we’ll delve into some key hurdles that researchers and developers need to address:

- Handling Ambiguous Entities:
LLMs can struggle with entities that have multiple meanings or interpretations, depending on the context. For example, “Apple” could refer to the fruit, the tech company, or a record label. Disambiguating such entities requires additional knowledge and reasoning capabilities that are still under development in LLMs.
- Domain-Specific Adaptations:
LLMs trained on general-purpose data may not perform optimally in specific domains with unique terminology and entity types. Adapting LLMs to domain-specific NER tasks often requires additional training data and fine-tuning techniques, which can be resource-intensive and time-consuming.
- Managing Large Model Sizes:
LLMs often come with substantial computational requirements, making them resource-intensive to train, deploy, and run. This can be a hurdle for real-world applications, especially for organizations with limited resources.
- Explainability and Bias:
LLMs can be complex “black boxes,” making it challenging to understand their reasoning and decision-making processes behind entity recognition. This lack of explainability can raise concerns about potential biases and fairness issues in their outputs.
- Data Quality and Availability:
The effectiveness of LLMs heavily depends on the quality and quantity of training data. Insufficient or biased data can lead to inaccurate and unreliable NER performance. Addressing data-related challenges remains crucial for ensuring robust and trustworthy models.
Potential Use Study: Leveraging BERT for Entity Typing
The application of advanced NLP techniques, such as fine-tuned BERT models, holds immense potential for enhancing entity typing tasks in various industries. Let’s explore how businesses can leverage BERT for entity typing to unlock valuable insights and drive innovation.
Introduction:
Entity typing, a crucial task in NLP, involves classifying entities into specific categories such as person, location, or organization. This classification enables systems to extract meaningful information from text, facilitating various business applications.
Approach:
By leveraging fine-tuned BERT models, businesses can achieve state-of-the-art performance in entity typing tasks. Fine-tuning BERT on diverse datasets allows organizations to capitalize on the model’s ability to capture complex linguistic patterns and contextual relationships within text.
Business Implications:
The potential implementation of entity typing with BERT offers significant implications for businesses:
- Enhanced Data Processing: Accurately classifying entities in text data streamlines information extraction processes, leading to improved data quality and efficiency.
- Advanced Semantic Understanding: BERT’s fine-grained entity typing enables businesses to gain deeper insights into their data, uncovering valuable connections and patterns that may have remained hidden otherwise.
- Customized Solutions: Leveraging BERT for entity typing empowers businesses to develop customized NLP solutions tailored to their specific domain and industry requirements.
Potential Applications:
The application of entity typing with BERT extends across numerous sectors, including:
- E-commerce: Enhancing product categorization and recommendation systems based on detailed entity classification.
- Healthcare: Facilitating the extraction of medical entities from patient records for improved diagnosis and treatment planning.
- Finance: Streamlining information retrieval and sentiment analysis in financial documents for better decision-making.
The potential use of BERT for entity typing underscores its transformative impact on real-world business applications. By harnessing the power of BERT, businesses can unlock new opportunities for data-driven insights and innovation across diverse domains.
Conclusion
Few-shot Named entity recognition presents a unique set of challenges and solutions, navigating the terrain of limited in-domain data while aiming for robust generalization. Prototypical networks, contrastive learning, meta-learning, and the prowess of large language models have all been explored to tackle this problem. The evolution of dedicated datasets like Few-NERD has further fueled progress, providing a standardized benchmark for evaluating few-shot NER models.
As we move forward, the interplay between advanced models, innovative methodologies, and meticulously curated datasets promises exciting developments in few-shot NER. The journey from simple dictionary-based approaches to the sophisticated fusion of meta-learning and LLMs exemplifies the dynamic landscape of NER research. With the continuous refinement of techniques and the emergence of new challenges, the future of few-shot NER holds immense potential for groundbreaking advancements in NLP.