
Introduction
From startups to established tech giants, the race to integrate AI capabilities into products and services is more competitive than ever. This innovation boom brings a plethora of opportunities for developers and founders eager to carve out their niche in the AI space. However, a major challenge that often stands in their way is the high cost associated with LLM API usage, which can significantly impact the financial viability of early-stage AI projects.
This article aims to address this issue head-on by providing practical strategies and tips to reduce LLM API costs. Our goal is to help developers and founders not only minimize expenses but also speed up the development and launch of profitable AI tools. Through these insights, we hope to make the journey into AI development more accessible and sustainable for innovators across the industry.
Precision in Prompt Engineering
Prompt engineering is both an art and a science, serving as a critical technique for interacting efficiently with Large Language Models (LLMs) like ChatGPT. By crafting precise and effective prompts, developers can significantly reduce the number of iterations and API calls needed to achieve the desired outcome.
This not only optimizes API usage costs but also improves the speed and relevance of responses. The process involves understanding the capabilities of the LLM, the context of the application, and the nuances of natural language instructions.
This can be achieved using multiple techniques each with its own level of effectiveness and ease of implementation.
The Cost-Effectiveness of Precise Prompt Engineering
To understand why precise prompt engineering leads to lower costs, consider the scenario of trying to extract specific information from a text using an LLM. With a low-accuracy prompt, you might need multiple iterations or follow-up questions to get the exact information you’re looking for. Each iteration represents an additional API call, which accumulates cost.
- Example of Low-Accuracy Prompting: Suppose you’re trying to extract the main themes from a novel for a book report. A vague prompt like “What is the book about?” might return a general summary that requires several follow-up queries to drill down to the themes, resulting in, say, 5 API calls.
- Example of High-Accuracy Prompting: Now, consider a more precise prompt: “Identify and explain the three main themes of the novel, focusing on their development and impact on the narrative.” This direct and detailed prompt is far more likely to yield a comprehensive response in just one attempt, thus requiring only 1 API call.
The Mathematical Rationale
If achieving a particular outcome (X) typically requires Y attempts with low-accuracy prompts and only Z attempts with high-accuracy prompts (with Z < Y), the reduction in required attempts directly translates to fewer API calls. For instance, if Y = 5 and Z = 1 for the same outcome, the cost savings are evident, as each API call has an associated cost.
Utilizing Prompt Templates Based on Use-Case Specifics
This approach focuses on designing prompt templates tailored to specific application contexts (e.g., customer service, content generation, coding assistance). This involves identifying the key information that needs to be conveyed in each use case and structuring prompts accordingly.
| Template: “As a customer support agent, respond to the customer’s inquiry with empathy, clarity, and actionable guidance. Ensure the response is concise and polite. Inquiry: ‘{{customer_inquiry}}’ Context: The customer ordered a product online and is asking about the status of their order. Provide a generic response that guides them on how to track their order or contact support for further assistance.”
Example Inquiry: “I ordered a book two weeks ago and it still hasn’t arrived. Can you update me on its status?” Filled Prompt: “As a customer support agent, respond to the customer’s inquiry with empathy, clarity, and actionable guidance. Ensure the response is concise and polite. Inquiry: ‘I ordered a book two weeks ago and it still hasn’t arrived. Can you update me on its status?’ Context: The customer ordered a product online and is asking about the status of their order. Provide a generic response that guides them on how to track their order or contact support for further assistance.” |
For example, we can utilize the above-specified prompt template for customer support. This approach increases the likelihood of receiving the desired response on the first attempt, reducing the need for follow-up queries.
In addition, we should implement A/B Testing for Prompt effectiveness. In this step, we will conduct A/B testing with different versions of prompts to determine which yields the most accurate and relevant responses with the least number of iterations.
The process is simple, divide your test queries into two or more groups, each using a different prompt style or structure. Measure the effectiveness based on response quality, relevance, and the number of iterations required.
To test the final results, we could store each prompt’s final output side by side and compare the results.
LMQLs (Language Model Query Language)
Newly introduced, LMQL or Language Model Query Language, introduces an even more structured approach to interacting with language models. It allows for the specification of more complex queries and instructions in a structured format, enabling more precise control over the output of language models.
LMQL can be thought of as a “programming language” for LLMs, where you can specify variables, logic, and even desired output formats directly within your prompts. This can greatly reduce the ambiguity in prompts and increase the efficiency of the interaction.
An example of LMQLs do include utilizng the @lmql.query which allows users to write LLM prompts in a way similar to Python functions.
| @lmql.query
def meaning_of_life(): ”’lmql # top-level strings are prompts “Q: What is the answer to life, the \ universe and everything?” # generation via (constrained) variables “A: [ANSWER]“ where \ len(ANSWER) < 120 and STOPS_AT(ANSWER, “.”) # results are directly accessible print(“LLM returned”, ANSWER) # use typed variables for guaranteed # output format “The answer is [NUM: int]“ # query programs are just functions return NUM ”’ # so from Python, you can just do this meaning_of_life() # 42 |
By allowing developers to specify more detailed instructions and desired outcomes, LMQL can lead to more accurate and relevant responses from LLMs.
With clearer instructions, the need for follow-up queries can decrease, thus reducing the overall API usage.
Smart Caching Mechanisms Utilizing APIs
Smart caching mechanisms play a pivotal role in optimizing the performance and cost-efficiency of applications utilizing Large Language Model (LLM) APIs. By strategically caching responses, developers can significantly reduce the number of redundant API calls, focusing on immutable and static responses that don’t change frequently. This approach not only minimizes latency and API costs but also enhances the user experience by providing faster response times.
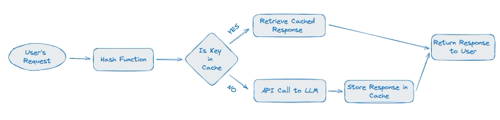
The first step in implementing effective caching is to identify which entities and responses are suitable for caching. Typically, responses that are static or immutable—meaning they do not change based on different user inputs or over short periods—are prime candidates for caching.
Examples include standardized responses to common queries, pre-computed analytical results, or any data that remains constant across sessions for all users.
Once cacheable entities are identified, the next step involves hashing response data to streamline retrieval processes. Hashing converts response data into a unique fixed-size string, which can then be used as a key in caching systems. This method ensures that identical requests can retrieve cached responses quickly without needing to recompute or make another API call.
For instance, consider a scenario where an application frequently requests sentiment analysis on common phrases. By hashing the input phrase and using it as a key, the application can instantly check if the sentiment analysis for that phrase is already cached, significantly reducing API calls to the LLM.
Fine-tuning and Using Smaller Models Locally
Fine-tuning smaller Large Language Models (LLMs) for specific tasks and running inferences locally or on edge devices presents a compelling alternative to relying solely on API-based solutions.
This approach can significantly reduce costs associated with API usage, providing a more sustainable and efficient pathway for deploying AI capabilities, especially for startups and developers keen on optimizing operational expenses.
Step-by-Step Guide to Fine-Tuning and Local Deployment
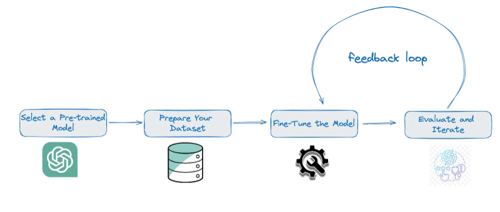
Select a Model: Begin with a smaller LLM that’s pre-trained, such as GPT-Neo or DistilGPT. These models offer a good trade-off between size and capability, making them ideal for fine-tuning.
- Prepare Your Dataset: Collect and preprocess the data specific to your task. This might involve cleaning the text, segmenting it into training and validation sets, and formatting it in a way that’s compatible with your model.
- Fine-Tune the Model: Use your dataset to fine-tune the model on your specific task. This process adjusts the model’s weights to perform better on your data, essentially customizing the model’s predictions to be more aligned with your requirements.
- Evaluate and Iterate: Test the fine-tuned model’s performance on a separate validation set. Use these results to adjust your fine-tuning process, such as by changing hyperparameters or adding more data.
Lastly, you can host the model onto your own server, vastly reducing the cost of using third-party chat APIs.
Conclusion
To sum up, the strategies outlined in this article illuminate a pathway for developers and founders to harness the power of Large Language Models (LLMs) more efficiently and cost-effectively.
From the nuanced art of prompt engineering to the strategic deployment of smart caching mechanisms, each approach offers a means to minimize LLM API usage while enhancing the functionality and speed of AI-powered tools. The adoption of Language Model Query Language (LMQL) introduces a structured method to interact with these models, promising greater precision and reduced iterations.
Additionally, the technique of fine-tuning and deploying smaller models locally presents an innovative alternative to traditional API-dependent development methods, potentially revolutionizing how we think about building and scaling AI applications.