
In today’s rapidly evolving digital landscape, the seamless and effective retrieval of information, guided by the integration of vectors, plays a pivotal role in determining success across diverse industries. As our reliance on vast data warehouses continues to grow, the ability to navigate and extract pertinent information with precision, harnessing the power of vectors, has become a cornerstone of efficient decision-making and problem-solving. Information retrieval, with vectors at the heart of our digital interactions, demands a systematic approach to identify, extract, and present relevant data from expansive databases.
This process not only empowers individuals and organizations with the knowledge needed to make informed choices but also underpins advancements in technology, research, and innovation. In this era of information abundance, mastering the art of information retrieval is key to unlocking the full potential of our digital age.
Historically, keyword-based search algorithms dominated this area, but despite their foundational significance, they typically struggle to offer consistently relevant and contextually acceptable results. The introduction of vector databases marks a watershed moment, drastically changing the operational paradigms of search and retrieval processes. This thorough explanation goes into the deep synergy between information retrieval and vector databases, demonstrating the significant influence of this integration in boosting the accuracy, contextuality, and relevancy of search.
Introduction to Information Retrieval with Vectors:
The foundation for accessing and utilizing the enormous information stores found in digital environments is information retrieval. It is carefully choosing pertinent content based on user searches from enormous collections, which may include papers, web pages, or databases. Conventional information retrieval methods, which mostly rely on keyword-based searches, have proved helpful but have several drawbacks. These systems struggle to grasp the complex semantics of language, the wide range of contextual factors that affect word choice, and the variety of linguistic expressions that characterize human communication.
Within this context, vector databases present a paradigmatic advance that moves away from traditional keyword-centric techniques and towards more complex, semantically aware ones. These databases make use of vectors, which are multidimensional representations of data that capture its essence and subtle contextual information. This move to vector-based information retrieval marks the beginning of a paradigm-shifting period in which search methods advance beyond straightforward keyword matching. Rather, they embrace a deep understanding of the context, relational complexity, and semantic richness that are inherent in the content.
Vector Representations for Text Documents:
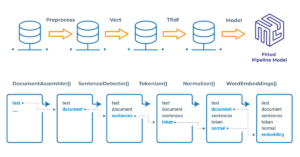
The conversion of textual information into vector representations is a cornerstone of modern information retrieval systems, catalyzing significant enhancements in their capabilities. Methodologies such as Term Frequency-Inverse Document Frequency (TF-IDF), word2vec, and Bidirectional Encoder Representations from Transformers (BERT) play a pivotal role in this transformation. These techniques transmute textual data into numerical vectors, encapsulating the frequency and occurrence of words and the rich context and intricate semantic relationships embedded within the text.
TF-IDF, for instance, assigns weights to words in a document, emphasizing the significance of a word relative to its frequency across a corpus of documents. This allows the system to discern the relative importance of terms within a specific contextual framework. Word2vec, leveraging neural network models, comprehends the linguistic contexts of words, mapping semantic meanings into a high-dimensional space, thereby capturing the multifaceted nature of language. BERT advances this paradigm by understanding the full context of words within sentences, analyzing the interplay of words before and after the target word, thereby encapsulating the nuances of language comprehensively.
These vector representations offer a profound advancement over traditional keyword-based indexing methodologies. They capture the subtleties of language, the context within which words are used, and the intricate web of semantic relationships, thereby enhancing the precision and contextual relevance of information retrieval. This not only augments the accuracy of the retrieval process but also ensures that the results are meticulously aligned with the contextual intent behind the user’s query, offering a more insightful, intuitive, and user-centric search experience.
Harnessing Vector Similarity Metrics for Optimal Results:
Vector embeddings have emerged as powerful tools across various domains, from natural language processing to computer vision. The comparison of vector embeddings and the assessment of their similarity play pivotal roles in semantic search, recommendation systems, anomaly detection, and beyond.
At the core of result production lies the careful consideration of vector similarity metrics. This article delves into three commonly used metrics: Euclidean distance, cosine similarity, and dot product similarity, providing insights into their benefits and limitations. A deeper understanding of these metrics empowers users to make informed decisions when choosing the most suitable similarity metric for their specific use cases.
The fundamental principle guiding the selection of a similarity metric is to align it with the one employed during the training of the embedding model. For instance, if the model was trained using cosine similarity, employing the same metric in the index will yield the most accurate results. This alignment ensures utilises the best algorithms for optimal outcomes.
Exploring these similarity metrics sheds light on how they operate beneath the surface, offering intuition into what it means for two vector embeddings to be considered similar in the context of a particular use case. In natural language processing, for instance, vectors representing word meanings may be deemed similar if used in comparable contexts or related to similar ideas. In recommendation systems, vectors reflecting user preferences could exhibit similarity when users share interests or make similar choices.
Euclidean Distance: Euclidean distance, representing the straight-line distance between two vectors in a multidimensional space, is calculated as the square root of the sum of the squared differences between the corresponding components. This metric is sensitive to scale and the relative location of vectors in space, making it ideal for scenarios where embeddings contain information related to counts or measures.
Dot Product Similarity: The dot product similarity metric involves adding the products of the corresponding components of two vectors. It is a scalar value, influenced by the length and direction of vectors. When vectors have the same length but different directions, the dot product is larger if they point in the same direction and smaller if they point in opposite directions. This metric is commonly used in large language models (LLMs) for training and serves as a suitable scoring function.
Cosine Similarity: Cosine similarity measures the angle between two vectors, calculated by taking the dot product and dividing it by the product of their magnitudes. Unaffected by vector size, cosine similarity indicates similarity based on direction. This metric is valuable for semantic search, document classification, and recommendation systems relying on past user behavior.
In conclusion, the strategic selection of a similarity metric is pivotal for optimizing the performance of vector embeddings within. Understanding the nuances of each metric enables users to align their choices with the characteristics of their data, ensuring precise and relevant results across diverse applications.
Increasing Search Precision:
When it comes to improving the accuracy and significance of search results, vector databases are clear leaders. These databases do more than just match keywords; they utilize complex vector representations and state-of-the-art similarity assessment techniques to provide results that match user intent.
Consider a person who is searching for “Apple.” Equipped with the contextual knowledge that vector representations offer, a vector-based search system may quickly determine if the user is referring to the fruit or the tech business. This increased degree of accuracy and contextual awareness is a significant shift from traditional search techniques, guaranteeing that search results are not just surface-level aligned with query words but also profoundly aligned with the user’s expectations and information demands.
Additionally, the capacity of vector databases to decipher and handle the contextual nuances and semantic complexities found in text results in a more satisfying, insightful, and nuanced search experience. Users are shown results that complement their search context and underlying purpose in addition to being consistent with the stated query words. This improves the usefulness of the material displayed as well as the general caliber and relevancy of search results.
To put it simply, vector databases are a paradigm shift in the search space, providing a more thoughtful and contextually aware method that elevates and enriches the user’s relationship with information.
Popular vector database algorithms:
Algorithms play a crucial role in the creation of efficient vector indexes, aiming to facilitate fast querying by constructing a data structure that enables swift traversal. These algorithms often transform the original vector representation into a compressed form, optimizing the query process.
As a user, you can rest assured that the platform seamlessly manages the intricacies and selection of these algorithms. takes care of the complexities and algorithmic decisions behind the scenes, ensuring optimal performance and results without any hassle. By leveraging expertise, you can focus on extracting valuable insights and delivering powerful AI solutions.
Let’s delve into a few algorithms and their distinct approaches to handling vector embeddings, empowering you to make informed decisions and appreciate seamless performance as you unlock the full potential of your application.
Random Projection: Random projection involves projecting high-dimensional vectors into a lower-dimensional space using a random projection matrix. This matrix, created with random numbers, facilitates a faster query process by reducing the dimensionality of the data. While random projection is an approximate method, its efficiency depends on the properties of the projection matrix.

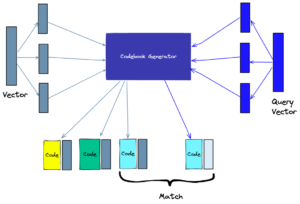
Product Quantization: Product quantization (PQ) employs a lossy compression technique for high-dimensional vectors. This technique involves splitting vectors into segments, training a “codebook” for each segment, encoding vectors using the codebook, and querying by breaking down vectors into sub-vectors and quantizing them using the same codebook. The number of representative vectors in the codebook is a trade-off between accuracy and computational cost.
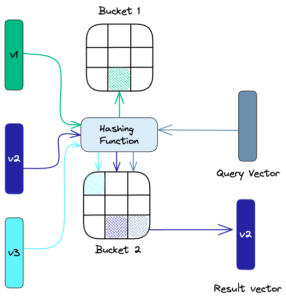
Locality-Sensitive Hashing (LSH): LSH is a technique for approximate nearest-neighbor search, mapping similar vectors into “buckets” using hashing functions. This method significantly speeds up the search process by reducing the number of vectors in each hash table. LSH is an approximate method, and the quality of the approximation depends on the properties of the hash functions.
Hierarchical Navigable Small World (HNSW): HNSW creates a hierarchical, tree-like structure where nodes represent sets of vectors and edges indicate similarity. Starting with a set of nodes, each with a small number of vectors, the algorithm draws edges between nodes with the most similar vectors. When querying an HNSW index, the graph is used to navigate through the tree, visiting nodes efficiently.

In your journey, these algorithms work in tandem to provide a robust foundation for vector-based information retrieval, ensuring your focus remains on meaningful insights and impactful AI solutions.
Conclusion:
The integration of vector databases into the information retrieval domain signifies a paradigmatic transformation, heralding an era of enhanced precision, relevance, and contextual awareness in search mechanisms. This confluence of advanced vector representations and sophisticated retrieval methodologies promises a future where information retrieval transcends mere data access, evolving into an intuitive, context-aware process. As we navigate this digital age, the role of vector databases in revolutionizing information retrieval is poised to become increasingly pivotal, shaping the future of how we interact with and leverage the vast expanse of digital information.